LinkedIn Social Listening & Nano-Trigger Detection Engine

For years, the standard playbook for CMOs and their teams was "social listening." You tracked your brand name, maybe a few competitors, and measured sentiment. That approach was fine for brand management—knowing if people generally liked or disliked you—but it’s not sufficient for identifying people with the problems you solve. The most sophisticated teams are now focusing on detecting "Nano-Triggers."
The Nano-Signal in the Noise
A Nano-Trigger isn’t just a keyword mention; it is a high-intent behavioral signal that is often buried deep in second-order interactions. These signals usually don't appear in the main headlines or posts on LinkedIn. Instead, they are hidden in the comments on the comments—the "whispers" of the market rather than the "shouts."
We are seeing a few specific patterns that consistently indicate buying intent, which traditional tools almost always miss:
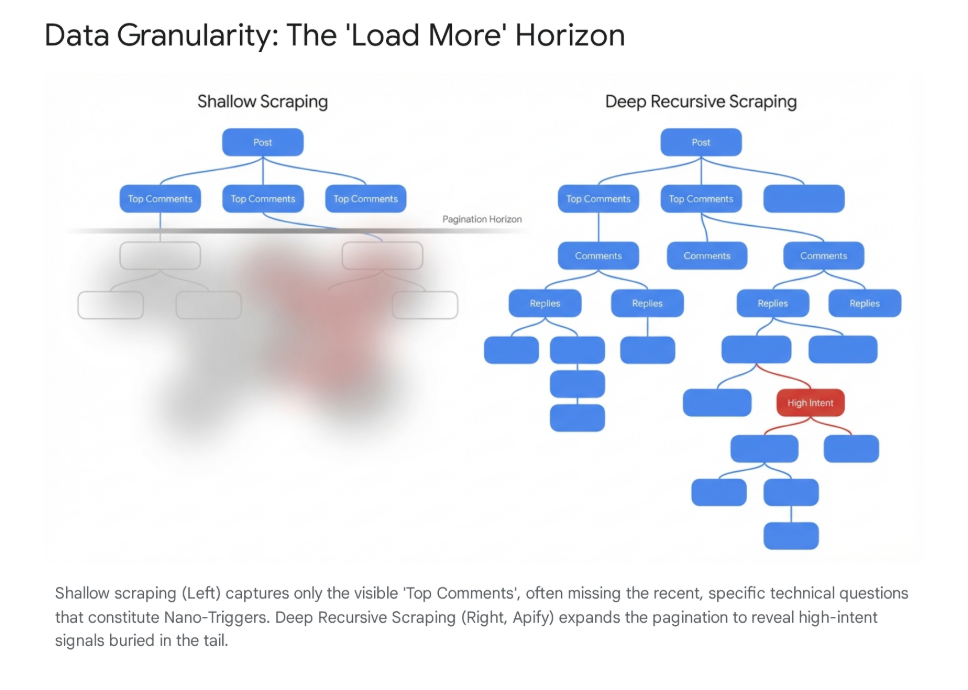
- The "Alternative" Query: This is the gold standard of intent. A prospect might reply to a thought leadership piece asking, "Does anyone know a better alternative to [Competitor X]?" or "Has anyone actually deployed this successfully?" This signals high churn intent and an immediate need. Because these queries often happen deep in a reply thread, they are invisible to standard listening tools that only scrape top-level posts.
- The Implementation Blocker: We frequently see users venting about specific technical hurdles. A comment like, "I've been struggling to get the API key working in HubSpot for weeks," is not just a complaint; it is a perfect opening for a support-led sales motion. If your product solves that friction point, that user is ready for a conversation today, not next quarter.
- The Budgetary Signal: This is subtler than a direct request for software. A team lead posting about hiring for a specific role (e.g., "We are looking for a Head of Demand Gen") is often a leading indicator that budget has been unlocked. That new hire will likely be evaluating and purchasing a tool stack within their first 90 days. Catching this signal early allows you to influence the requirement list before an RFP is even written.
- The Competitor Detraction: This occurs when a user explicitly mentions why they left a competitor. "We churned because their support was non-existent." This provides your sales team with the exact battlecard they need to win the deal: "We prioritize support."
The challenge—and the opportunity—is that these signals are incredibly difficult to capture technically. They require a level of "deep parsing" that most marketing stacks aren't built to handle.
The "Walled Garden" Challenge
If you have ever asked your engineering or marketing ops leads why we can't just "listen to everything on LinkedIn," they have likely given you a headache-inducing answer about APIs and permissions.
Here is the problem: LinkedIn operates as a "walled garden." Their official API is fundamentally designed for Community Management, not Market Monitoring. It allows you to manage your own brand's posts and reply to people talking to you. It does not allow you to listen to what the market is saying elsewhere—on competitor pages, in industry groups, or on influencer posts.
So the official, compliant path doesn't give you the data you need to find these Nano-Triggers. It essentially blinds you to the broader market conversation, leaving you reactive rather than proactive.
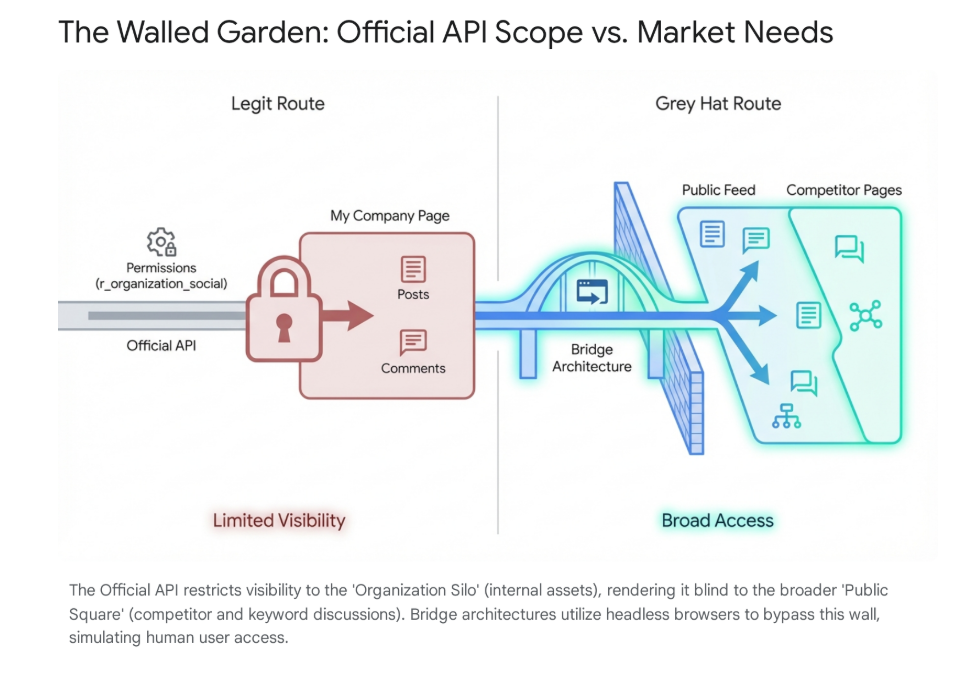
The Solution Landscape: Choosing Your Bridge
To solve this, rather than relying on the limited official pipelines, teams are using tools to bridge the gap between the data available and the data required for revenue generation.
In my recent analysis, three distinct approaches have emerged. Each serves a different level of technical maturity and risk tolerance:
1. The Velocity Play: Octolens & Buska
For teams that need "speed to insight" with minimal engineering overhead, tools like Octolens (or similar SaaS wrappers like Buska) are emerging as the preferred choice. These function effectively as "Data-as-a-Service," abstracting away the complexity of scraping.
- Capabilities: These tools provide a clean UI to set keywords and boolean logic (e.g., "CRM" AND "expensive"). The standout feature is their "Push" architecture—they send data to your systems via webhooks instantly when found. They also employ internal AI to pre-score mentions, filtering out some noise before it hits your dashboard.
- Pros:
- Zero Engineering: No scripts to write or servers to maintain.
- Real-Time Alerts: The webhook architecture means you get the signal the moment it happens, not hours later.
- Safety: The scraping happens entirely on their infrastructure using their accounts, isolating you from compliance risks.
- Cons:
- Black Box Filtering: You rely on their definition of a "relevant mention." If their internal AI deems a subtle Nano-Trigger as "low quality," you might never see it.
- Less Granular: You generally get the specific mention, but not necessarily the entire conversation tree surrounding it.
- Risk Profile: Low. This is effectively outsourcing the risk to the vendor.
2. The Granularity Play: Apify
For engineering-led growth teams that want raw power and total control, Apify acts as a programmable cloud browser. This is for teams building a proprietary data asset.
- Capabilities: Apify allows you to run dockerized scripts (Actors) that can simulate a complex human browsing session. It can perform deep recursion—clicking "load more comments" twenty times to find a buried implementation question. It returns raw, rich JSON data containing every available metadata field.
- Pros:
- Total Data Sovereignty: You get everything. If you want to train a custom model on 10,000 historical comments, this is the only way to get that data.
- Complex Logic: You can script specific behaviors, like "only scrape comments from users with 'CTO' in their headline."
- Cons:
- High Engineering Overhead: It requires a "Polling" architecture (constantly asking "is the data ready?"), which increases logic complexity.
- Variable Costs: You pay for compute time. Deep scrapes on viral posts can consume massive resources, making costs harder to predict.
- Risk Profile: Moderate. You typically use "burner" accounts and residential proxies to protect your main brand assets, but the responsibility for compliance management sits with your team.
3. The Legacy Play: Phantombuster
You might hear this name often in growth hacking circles—it was the industry standard for years—but we are seeing it fall out of favor for continuous monitoring.
- Capabilities: Phantombuster is a session-based automator. It focuses on batch processing—executing a specific action (like "extract these 50 profiles") on a schedule. It typically outputs data to CSV files rather than real-time streams.
- Pros:
- Simple Batching: It remains excellent for one-off tasks, like building a static list of attendees from a webinar or enriching a spreadsheet of leads.
- Cons:
- Cookie Fragility: This is the dealbreaker for "always-on" listening. It relies on your personal session cookie. If you log out, or if LinkedIn refreshes your session, the automation breaks immediately.
- Identity Linkage: Because it uses your cookie, LinkedIn can directly correlate the scraping activity to your personal profile.
- Latency: It is not event-driven. You might only catch a signal 24 hours after it happened, by which time the opportunity is cold.
- Risk Profile: High. Persistent, aggressive use can lead to warnings or restrictions on your personal LinkedIn account.

The Operational Reality: Filtering the Noise
Selecting the tool is only half the battle. The real magic is in the orchestration layer.
Raw social data is about 80% noise. If you simply forwarded every mention of "CRM" or "Sales Process" to your sales team, they would mute the channel within an hour. The volume of "Congrats on the new role!" and generic marketing fluff is simply too high.
This is where we layer in an orchestration tool (like n8n) combined with a Large Language Model (LLM).
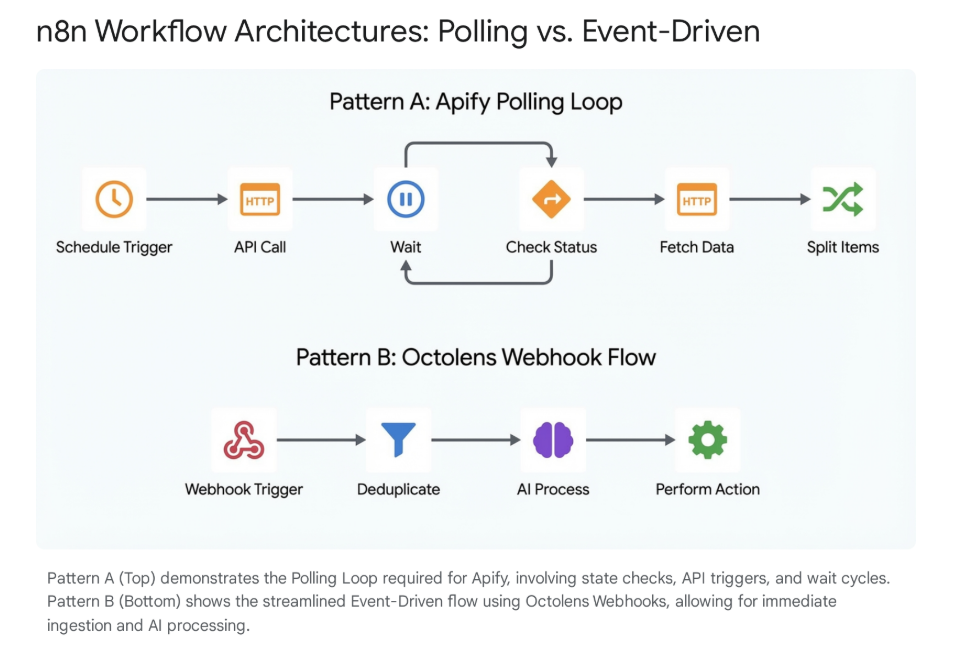
By passing the raw data through an AI filter before it reaches a human, we can strip away the noise. We can instruct the AI to:
- Discard generic engagement or recruiting spam.
- Deduplicate the conversation so you don't get alerted five times for the same thread.
- Classify the intent. A pricing question routes to Sales; a technical complaint routes to Support; a partnership opportunity routes to the CEO.
The Executive Takeaway
For the C-Suite, the takeaway is simple: We need to stop waiting for prospects to fill out a form.
The market has changed. The highest-intent conversations are happening in public, but they are happening in the margins—in the comments and replies where users feel safe discussing their real problems.
It is worth exploring with your revenue operations and marketing teams whether your current stack is set up to capture these signals. If you are relying solely on official integrations or fragile legacy scripts, you are likely missing the most valuable conversations in your market—and your competitors might already be listening.
Thanks for reading.
Troy